+-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
#交互式安装 In order to continue the installation process, please review the license agreement. Please, press ENTER to continue >>> #按ENTER浏览License Do you accept the license terms? [yes|no] >>> Please answer 'yes' or 'no':' >>> yes #yes回车同意接受License
Miniconda3 will now be installed into this location: /root/miniconda3
- Press ENTER to confirm the location - Press CTRL-C to abort the installation - Or specify a different location below
Do you wish to update your shell profile to automatically initialize conda? This will activate conda on startup and change the command prompt when activated. If you'd prefer that conda's base environment not be activated on startup, run the following command when conda is activated:
conda config --set auto_activate_base false
You can undo this by running `conda init --reverse $SHELL`? [yes|no] [no] >>> yes #登录shell时自动激活conda,输入yes
==> For changes to take effect, close and re-open your current shell. <==
+-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | 0 N/A N/A 207341 C ...l/models/myenv/bin/python3.13 77870MiB | | 1 N/A N/A 207358 C ...l/models/myenv/bin/python3.13 77870MiB | +-----------------------------------------------------------------------------------------+
#注意: 确保CUDA_HOME环境变量已设置,如果没有设置会报错!!!! In file included from /usr/include/crt/math_functions.h:9075, from /usr/include/crt/common_functions.h:303, from /usr/include/cuda_runtime.h:115, from <command-line>: /usr/include/c++/11/cmath:45:15: fatal error: math.h: No such file or directory 45 | #include_next <math.h> | ^~~~~~~~ compilation terminated. In file included from /usr/include/crt/math_functions.h:9075, from /usr/include/crt/common_functions.h:303, from /usr/include/cuda_runtime.h:115, from <command-line>: /usr/include/c++/11/cmath:45:15: fatal error: math.h: No such file or directory 45 | #include_next <math.h> | ^~~~~~~~ compilation terminated. fatal : Could not open input file /tmp/tmpxft_0003aaba_00000000-7_batch_prefill_ragged_kernel_mask_2.cpp1.ii ninja: build stopped: subcommand failed.
Possible solutions: 1. set --mem-fraction-static to a smaller value (e.g., 0.8 or 0.7) 2. set --cuda-graph-max-bs to a smaller value (e.g., 16) 3. disable torch compile by not using --enable-torch-compile 4. disable CUDA graph by --disable-cuda-graph. (Not recommended. Huge performance loss) Open an issue on GitHub https://github.com/sgl-project/sglang/issues/new/choose
[2025-07-02 11:51:47] Received sigquit from a child process. It usually means the child failed. [2025-07-02 11:51:47] Received sigquit from a child process. It usually means the child failed. Killed
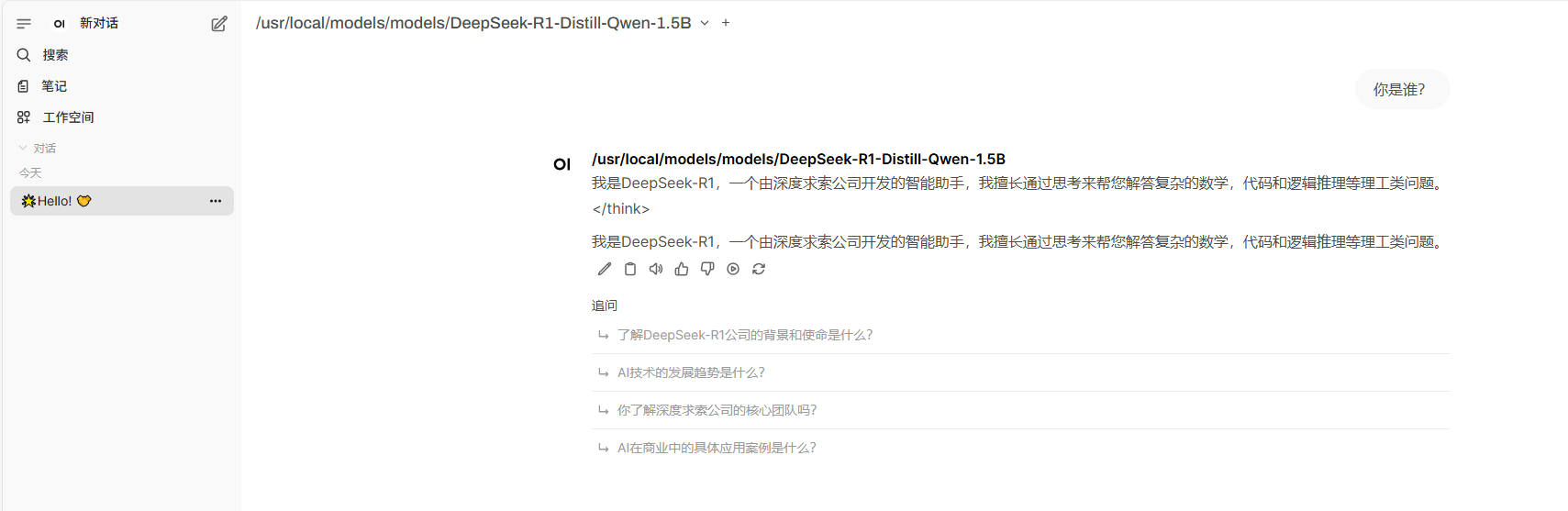
#模型启动检查 #日志显示启动成功 [2025-07-02 11:53:43] INFO: Started server process [240755] [2025-07-02 11:53:43] INFO: Waiting for application startup. [2025-07-02 11:53:43] INFO: Application startup complete. [2025-07-02 11:53:43] INFO: Uvicorn running on http://127.0.0.1:30000 (Press CTRL+C to quit) [2025-07-02 11:53:44] INFO: 127.0.0.1:55666 - "GET /get_model_info HTTP/1.1" 200 OK [2025-07-02 11:53:49] INFO: 127.0.0.1:55680 - "POST /generate HTTP/1.1" 200 OK [2025-07-02 11:53:49] The server is fired up and ready to roll!
+-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | 0 N/A N/A 207341 C ...l/models/myenv/bin/python3.13 77870MiB | | 1 N/A N/A 207358 C ...l/models/myenv/bin/python3.13 77870MiB | +-----------------------------------------------------------------------------------------+